🚧 page under construction – August 2022 🚧
In 2015 I developed an evolutionary robotics platform that generates behaviours for 3D agents which comprise both planning and locomotive actions. The agent behaviours are very lifelike and one of only a few examples of evolved AI that does more than locomotion. An overview of this work was published in a paper at the Artificial Life conference held in York, U.K. that year.
Since then I have occasionally returned to this work and picked apart the system to try to identify the most important parts of the design and hopefully to write a more comprehensive paper to further spread the ideas. This page brings together this work with some writing and annotated images and video.
The results that I originally presented were a proof-of-concept showing that the incremental evolutionary system and hybrid neurocontroller design worked to solve a problem requiring locomotion and planning. The problem I chose was based on an earlier paper by Robinson, Ellis and Channon (2007) where 2D agent behaviour was evolved to solve a deliberative task requiring the agents to collect objects in order to build a bridge to reach a resource. I built this problem in a 3D world instead, hoping that by augmenting the neurocontroller with additional capability to control the agents’ bodies in 3D I would hit on a recipe for more complex behaviours.
My optimism paid off: the combination worked to produce agents that not only walked around in their worlds but could also navigate to a target resource and build a (rather abstract) bridge, all using a policy learnt over evolutionary time. The behaviour of the simulated robots in the system often seems quite lifelike, and in many replicates it is easy to ascribe an agency to their actions in the way we do with living animals.
Design
The design is documented in more detail in the 2015 paper but in brief there are three key components: the river-crossing (RC) problem, the evolutionary system, and the controller and agent architectures. The underlying RC problem (closely following Robinson [2007]) sets agents in a 20-by-20 grid world where each grid cell can be one of a number of types: grass (i.e. empty), food, trap and resource. In the problem, agents move freely over grass and food (which they collect en route), are killed by traps, and are considered winning when they step on the resource. Additionally, the world can contain water (which again kills agents if they move onto it) and stones. The world permits agents to pick up stones and put them on water, thus building a bridge. Where water is present in the world, the resource is located across the water from the agents’ starting positions so it is necessary to build a bridge to succeed. In 3DRC, this abstract 2D world is implemented within a 3D rigid-body simulation of an articulated robot. This greatly increases the challenge of using evolution to discover good solutions to the RC problem because, in addition to solving the problem of avoiding traps and building the bridge with abstract actions (actions that are baked into the world in Robinson [2007] and others), agents must also adapt the physical control of their bodies to implement movement in the RC world from scratch.
Agents’ worlds are divided into levels that reflect increasing competency in the 3DRC problem. Successful completion of these levels (i.e. reaching the grid cell where the resource is found) confers evolutionary fitness on agents, as does collecting food.
- Food level – a world with a scattering of food and a resource.
- “Gallop” level – a single object, the resource, that the agent must reach.
- Stones and Traps – a world with a scattering of stones and traps, and a resource.
- 1-wide river – a 1-cell wide water hazard, in a world with stones and traps (and a distant resource).
- 2-wide river – as above, but 2-cells wide.
- 4-wide river – as above, but 4-cells wide.






Evolutionary System
I used a simple tournament selection model, where three individuals are evaluated and the one with the lowest accumulated fitness after 600 seconds of evaluation gets replaced by an offspring of the two winners. Successful completion of a level confers fitness of +100, and picking up a food item is a gain of +1. When agents complete level 6 they begin again at level 1, keeping the fitness they have accrued so far.
Agent and Controller Design
I used Open Dynamics Engine as the underlying rigid-body physics model. The agents’ worlds are very simple: a flat plane supports the articulated robot body. The body is a quadruped; each of the four legs has a knee and a 2-DOF hip joint and the legs are affixed to the torso at its corners. Motors drive the hips and knees, driven by signals from the robot controller via a proportional-derivative function that relates desired angles to actual angles.
The 2D, river-crossing grid-world is implemented as in Robinson (2007). An abstract data structure models the grid, and the saliency map generated by the shunting neural network is also stored as a discrete array.
The neurocontroller comprises three sub-components: the decision network, the physical network, and the pattern generator network. At each update step, the decision network (DN) samples the 2D RC world at the agent’s position and generates saliency, an “importance” measure, for each object (stone, trap, etc.) in the world (note that the agent’s position on the grid is discretized from its continuous position in 3D space on the plane). The generated saliency values are applied at each object’s location in the shunting network and diffused over the whole 2D RC grid area to produce the activity landscape, again in the abstract 2D environment. The 3D agent’s position is then used to sample the activity landscape at four points on the agent’s body (the collected values are derived by bilinear interpolation from the discrete 2D grid). These four values (as well as another four values that provide a one-hot encoding of the agent-relative direction of strongest signal) are used as inputs to the physical network (PN), a fully-connected 2-layer MLP.
The agents’ movement in the world is generated by recurrent neural circuits that are analagous to central pattern generators in biological organisms. This pattern generator network (PGN) is composed of five three-neuron motifs that are pre-evolved to produce sinusoidal oscillating signals. The MLP outputs are used directly as inputs to the PGN; the five PGN outputs (one from each of the five motifs) is combined by weighted sum into a representation of a target joint angle for each of the 12 joint motors; it is these values that are the inputs to the proportional-derivative function mentioned above.
Evolutionary adaptation affects the weights in the decision network, the weights in the physical network, the recurrent interneuron weights in the pattern generator network, and the weights from PGN to the target angle outputs.
Further Investigations
Once I saw that the system was working, I thought about the components that I had put in to get things going. There were (so I thought) four key ingredients needed to make the 3DRC environment generate effective behaviours in the agents:
- Pre-evolution of oscillating signals in the recurrent leaky-integrator “pattern generator” component;
- the “physical network” that pre-processes input signal before sending them to the pattern generator (i.e. the motor controller);
- the use of the “food” stage in evolution that promotes development of fast, effective locomotion and turning early on in a species’ lifetime; and
- the incremental stages that scaffold populations towards solutions to the 3DRC deliberative planning problem.
I thought that removing each of these components in turn would shed some light on their importance as parts of the solution. Their sufficiency in addressing the task was shown in the proof-of-concept, but their necessity was not. This could perhaps be shown by selectively disabling each of the four major parts.
As in the proof-of-concept, I ran 20 replicates for each of the four experiments. The data I collected were a record of where in the river-crossing world tournaments ended: highly successful populations ended on the four-wide river or sometimes even passed this stage. Poor populations were unable to even find the resource to move on from the level one “food” stage. By aggregating these results in bins of 1000 tournaments, I tracked the development of the populations over evolutionary time and was then able to compare the effects of removing the different components.
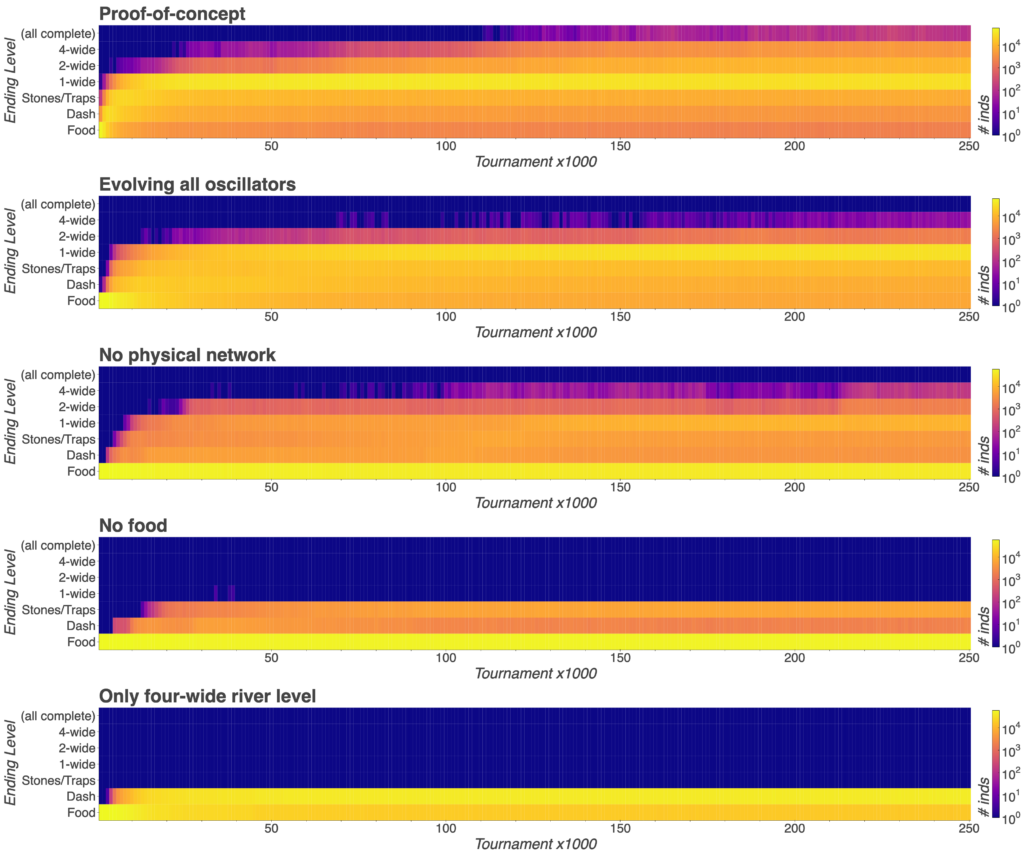
I also collected some more qualitative data by simple observation of the gaits and trajectories of the evolved agents. To do this, I constructed some custom “test scenario” environments that elicit particular responses from the agents. I had seen agents galloping towards their objectives, orienting themselves, and recoiling from sudden hazards so the environments were designed to promote these behaviours.

I tested each of the best agents from each of the 20 replicates of each of the four experiments, plus the proof-of-concept, in these environments and recorded their trajectories. As expected, the proof-of-concept showed the most capability in solving the challenges.
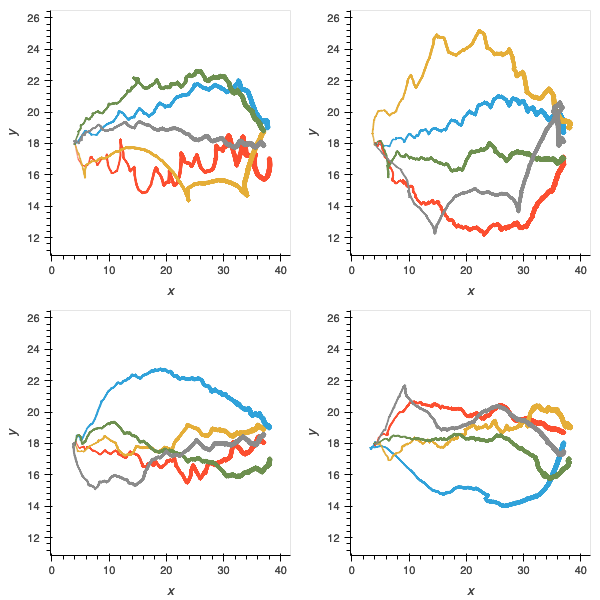
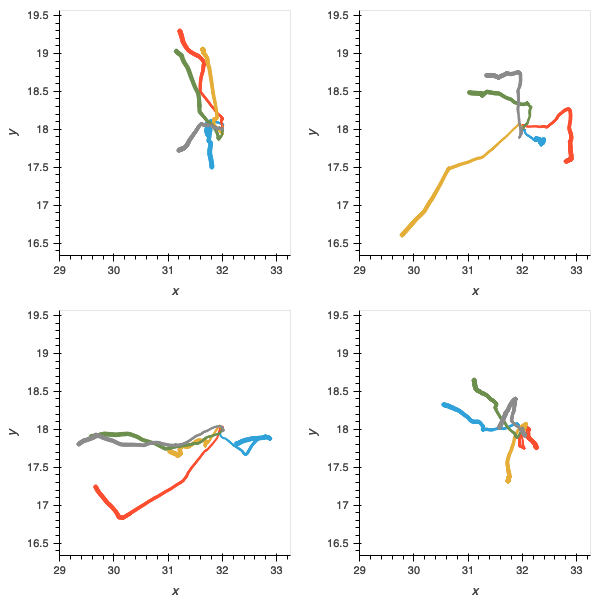
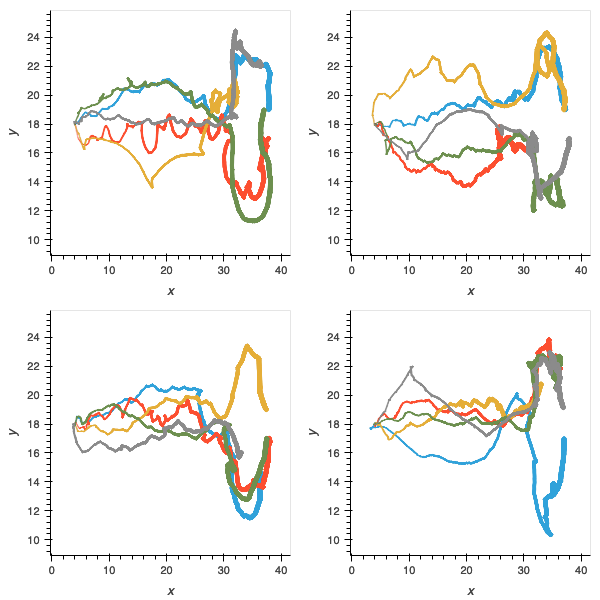
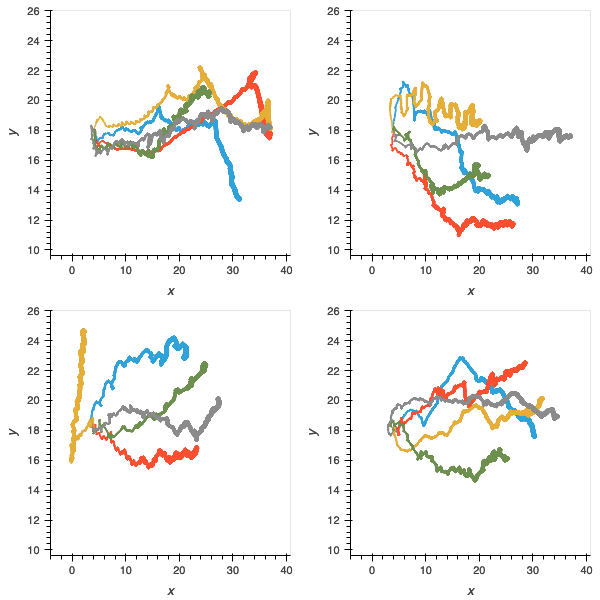
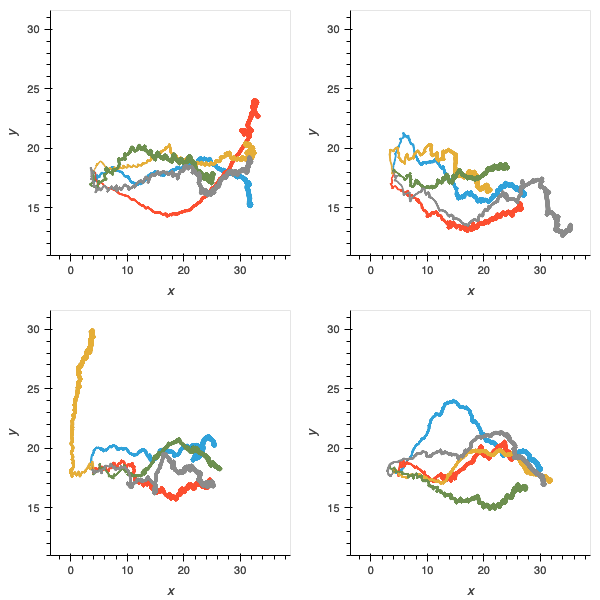
Figure 8: trajectories of populations without pre-evolved oscillator circuits in gallop (left); orient (middle); and recoil (right). Accuracy of gait is compromised, as is ability to orient and deal with the unexpected hazards.
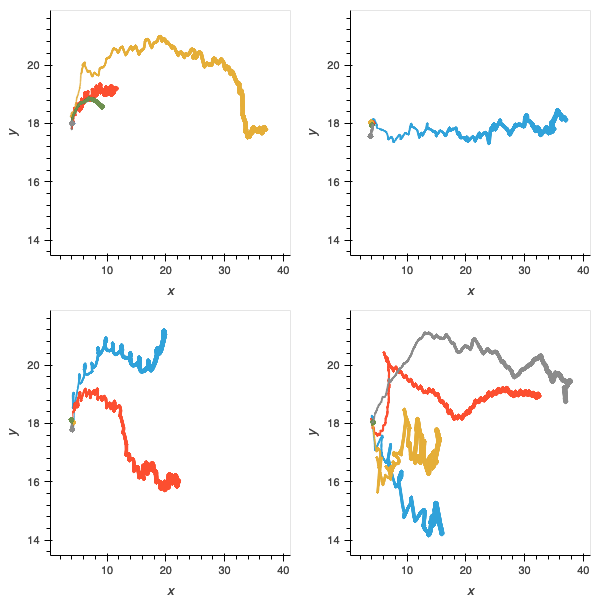
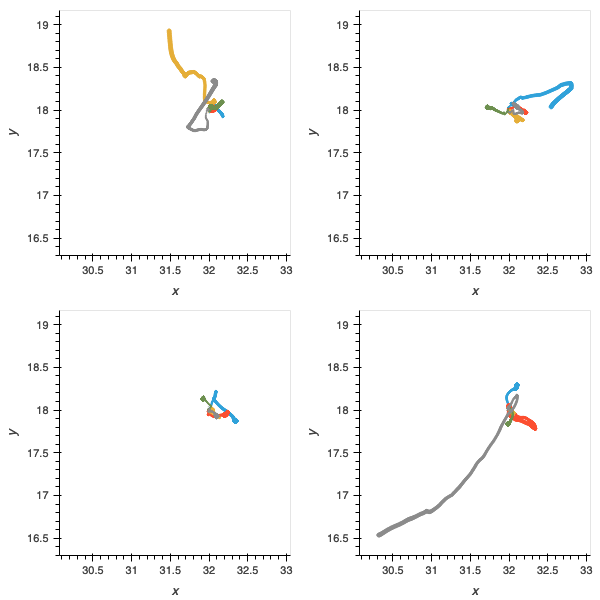
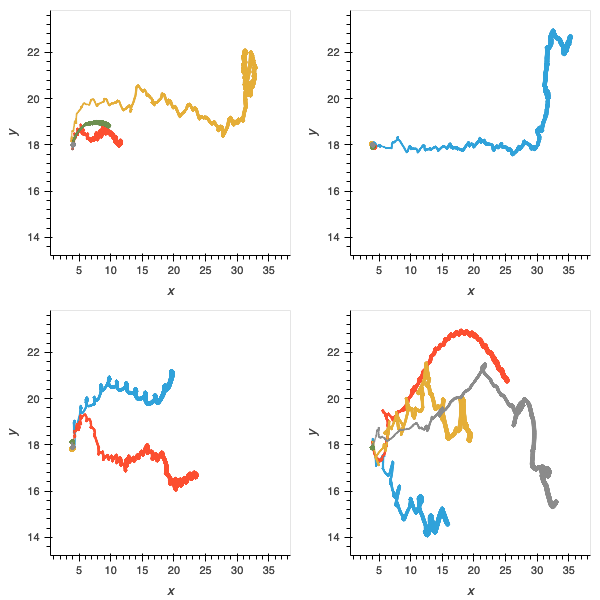
Figure 9: without the physical network component, performance on all trials is further compromised and few populations have delivered agents able to solve the challenges.
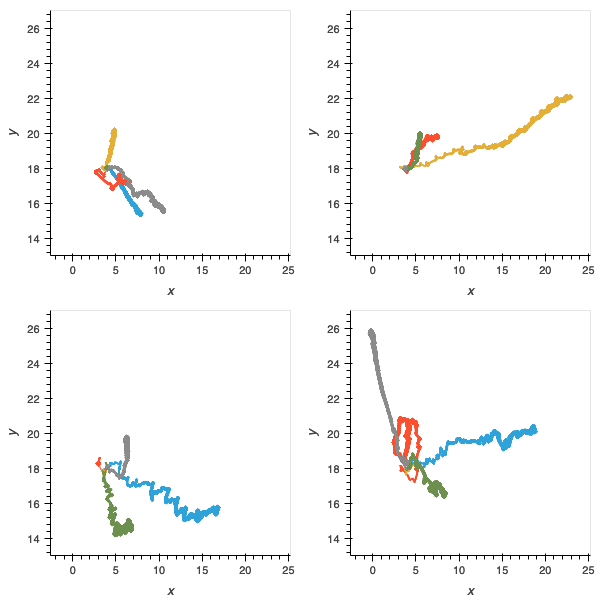
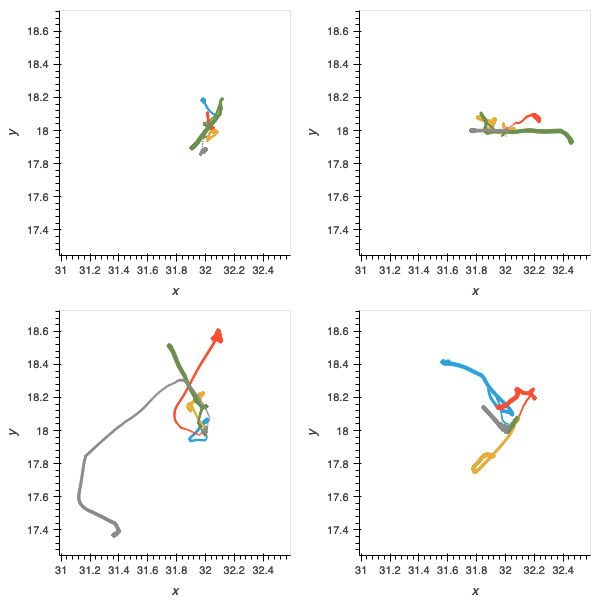
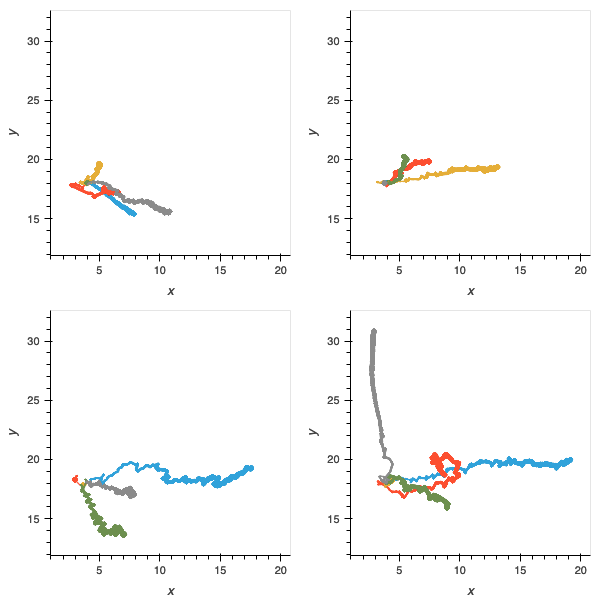
Figure 10: without the scaffolding of the “food” environment, agents are very poor at navigation and locomotion.
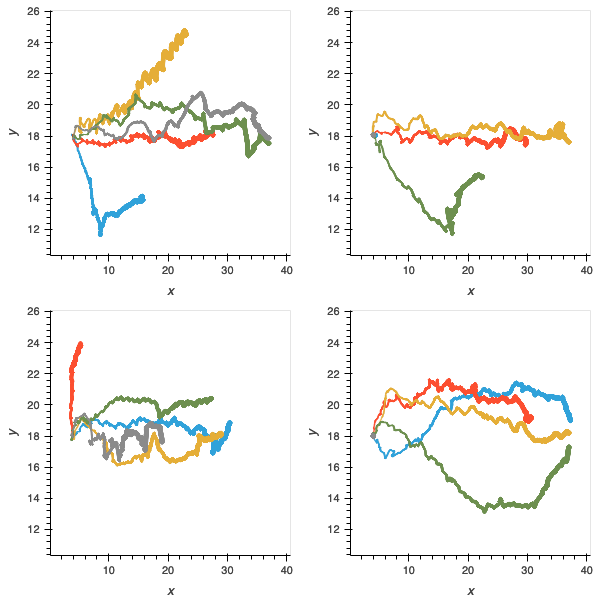
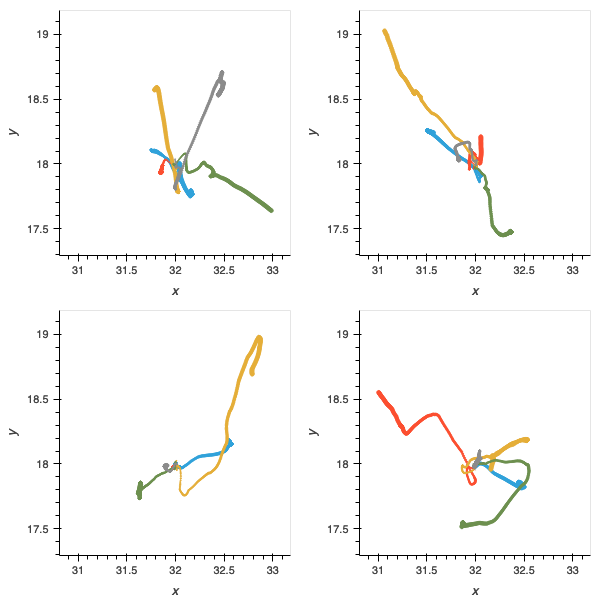
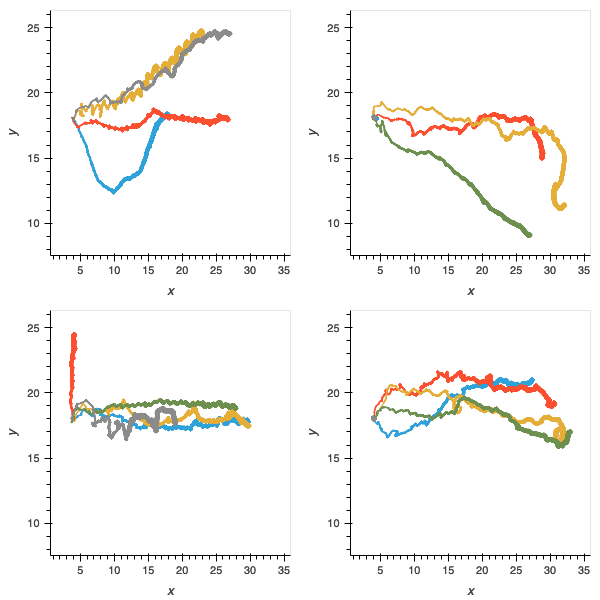
Figure 10: without the incremental task, agents are more proficient in navigation and locomotion but as shown in figure 4, are not able to solve later parts of the deliberative problem.
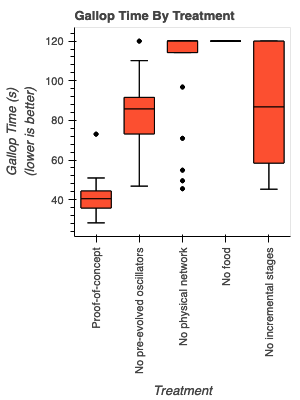
I also timed the replicates in the gallop test and aggregated this measure to get a view of how effective the evolved gaits are across the different treatments. It’s very clear from this analysis that the food level is very important in bootstrapping locomotion, and the box-whisker plots also show how much better the proof-of-concept is than the other experiments.
Conclusions and Take-Aways
- The components integrated in the proof-of-concept are sufficient to produce goal-directed (i.e. deliberative) behaviours in evolved 3D agents.
- This integration also results in agents that display qualitatively lifelike multimodal behaviours that are activated by environmental releasers.
- The “food” stage is crucial to encouraging effective locomotion in evolving species; species without this experience are unable to attempt later parts of the RC problem because their movement is not fast enough to give them sufficient time on the later RC levels.
- The incremental stages are crucial to learning basic parts of the RC problem. Species evolved only in the final stage are unable to attempt even the “stones and traps” level – this is because success at avoiding traps in the final stage does not confer fitness unless the bridge is built and the resource collected.
- Removing the pre-evolved oscillators causes less fluid behaviour and slower evolution, though it is possible that given enough time these populations would also be competitive in the final RC level.
- Removing the physical network has a compounding effect on the efficacy of movement in evolved agents.